
本文演示如何在 Kubernetes 环境下,基于 TaskManager 实例的资源使用情况,实现 Flink 作业的自动弹性扩缩容。
新建作业
在作业开发页面新建作业草稿,或直接使用内置的 demo_jar 作业,依次选择:,依次选择:"Flink 版本" → "Kubernetes Application 模式":
扩缩容配置
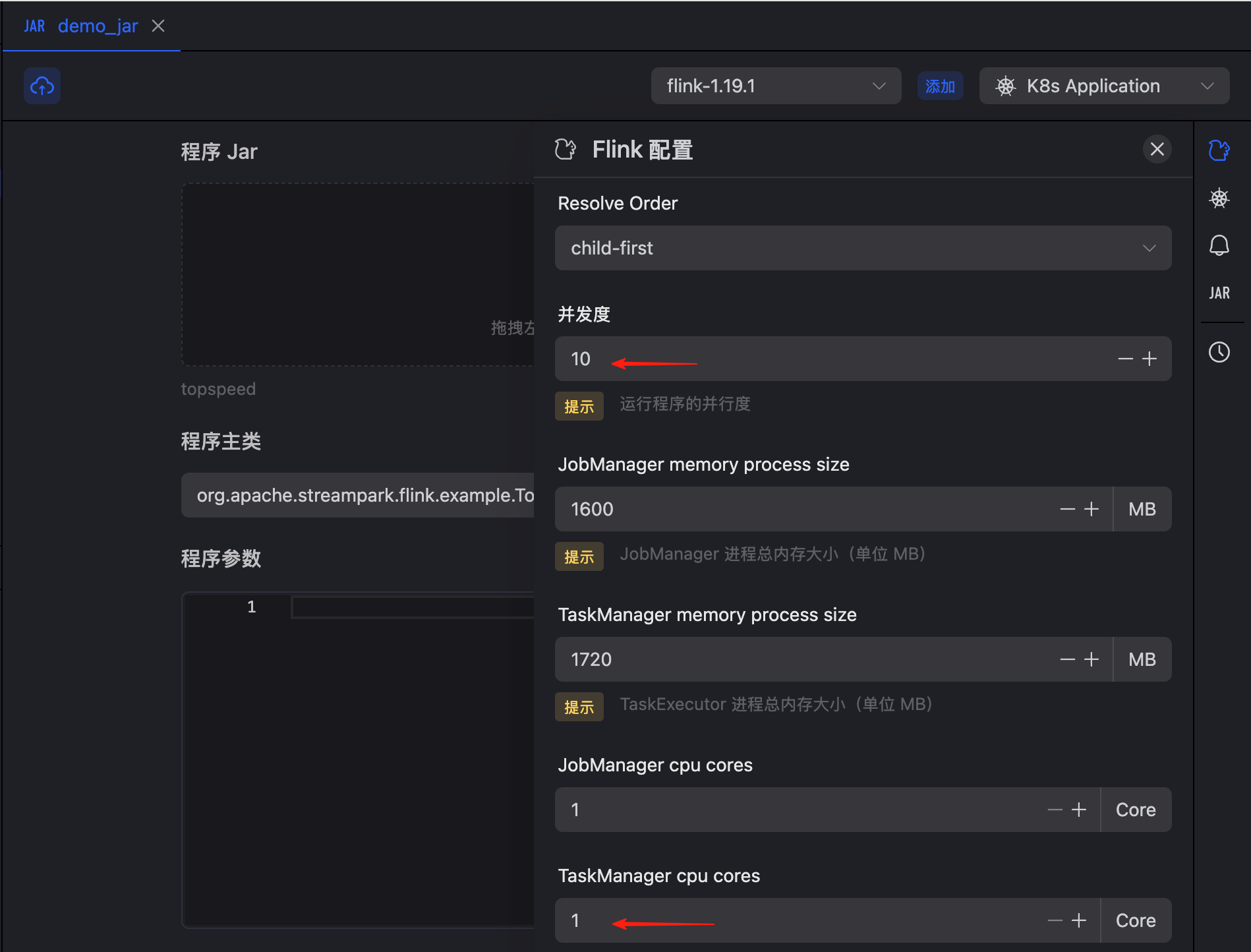
作业并行度及 CPU 配额限制
点击右侧配置栏的 Flink 按钮,展开后,配置并行度为 10,单个 TaskManager CPU 配额:1 核(1000m):
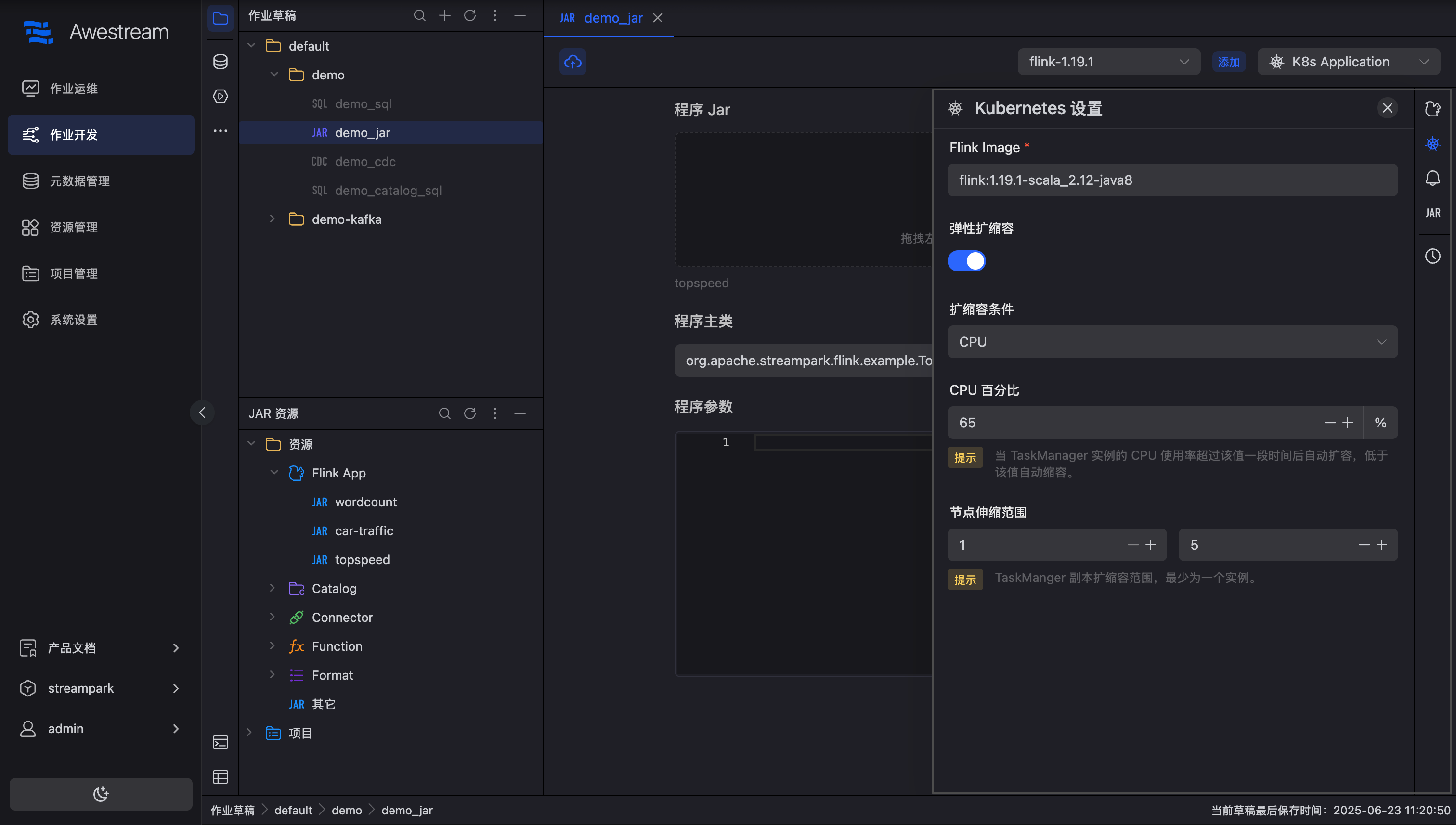
配置扩缩容条件
点击右侧配置栏的 kubernetes 按钮,打开弹性扩缩容开关,可以看到配置如下:
其中的扩缩容条件,支持如下几种:
| 类型 | 备注 |
|---|---|
| CPU | 根据 TaskManager CPU 利用率动态调整实例数量 |
| 内存 | 根据 TaskManager 内存利用率动态调整实例数量 |
| CPU和内存 | 同时根据 CPU 和内存利用率动态调整 |
| 自定义规则 | 支持基于自定义 Flink 指标(如 backlog、延迟、Watermark 滞后等)扩缩容 |
如上图所示,这里设置为 基于 CPU 作为扩缩容条件,当 CPU 百分比大于 65%,TaskManager 会进行自动扩缩容,副本数最小为 1,最大不能超过 5。
上线启动作业
继续点击作业上线,直至上线成功:
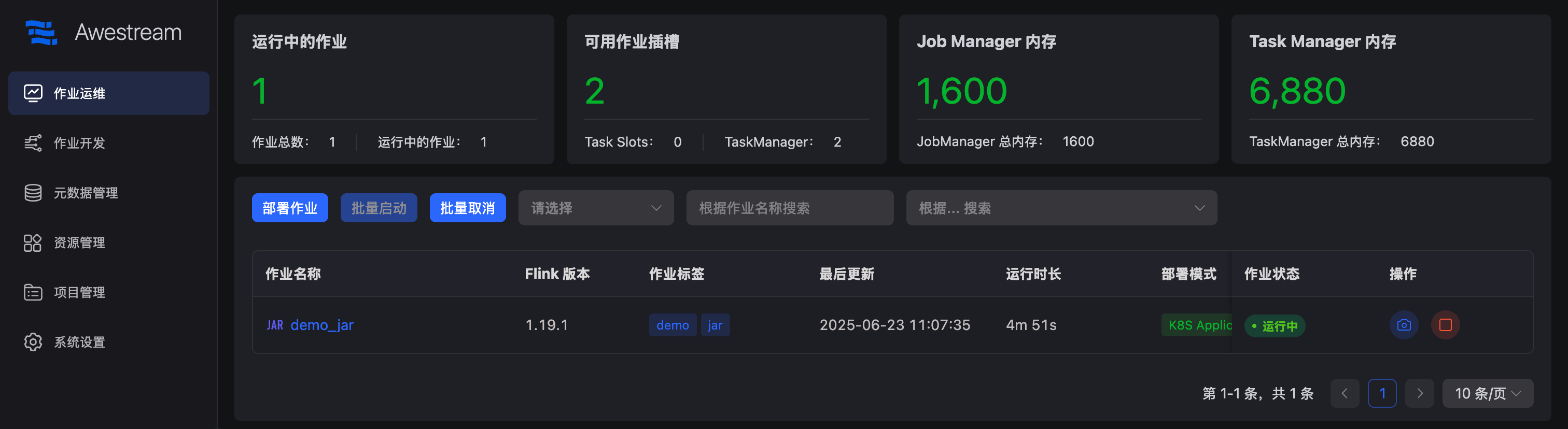
跳转至作业运维中心,点击启动按钮启动作业:
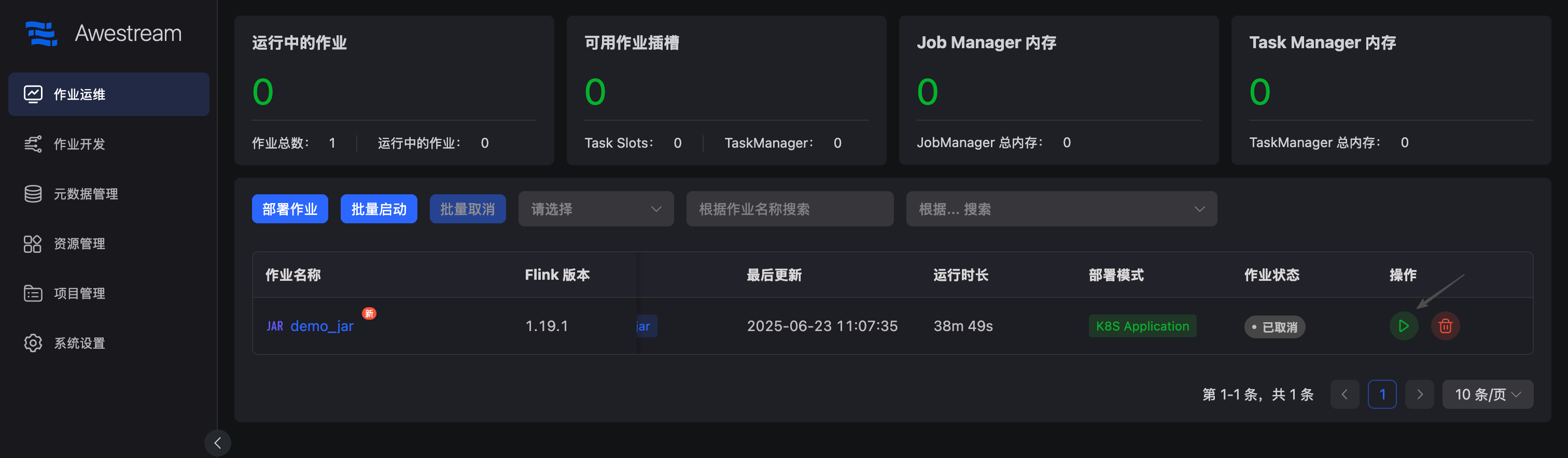
作业运行成功:
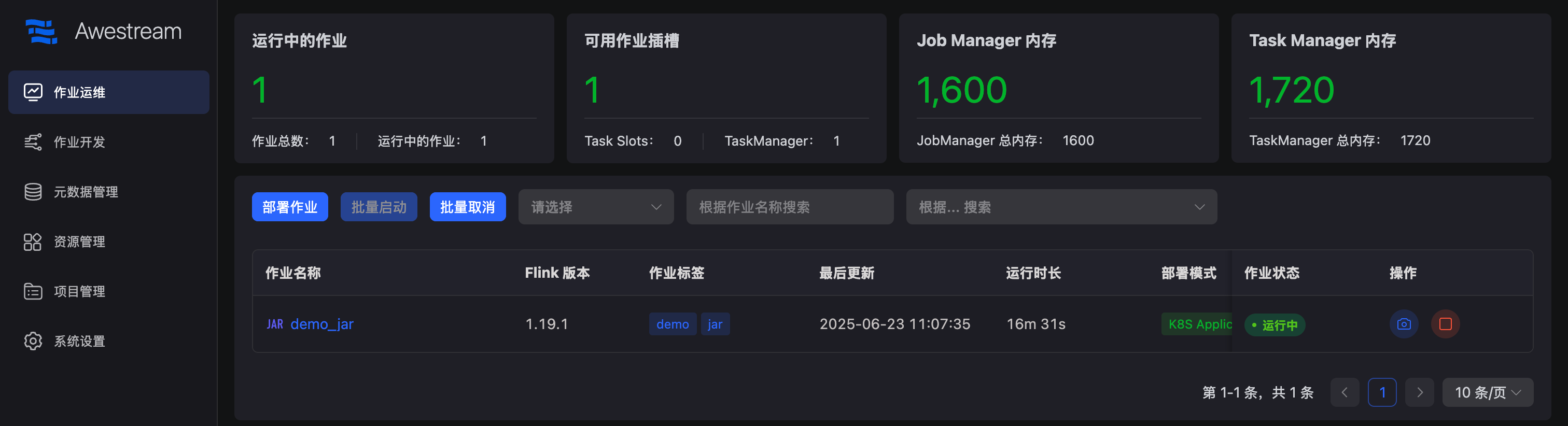
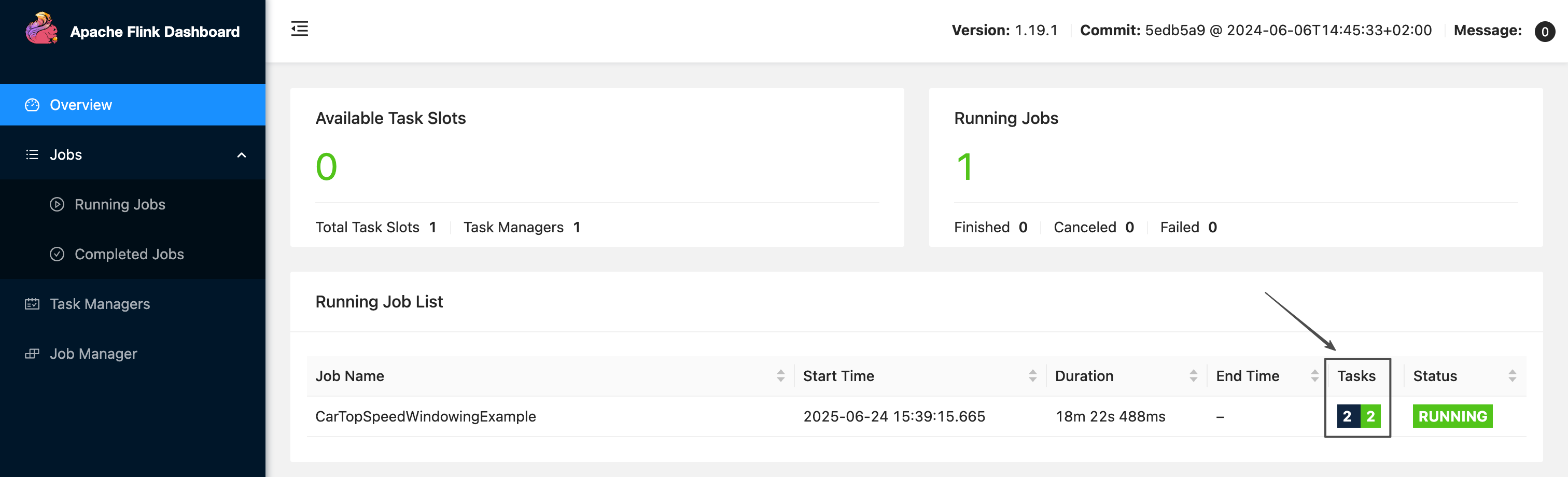
进入 "作业详情 → 作业状态",点击 “Apache Flink UI”,可以看到当前作业运行正常,且 tasks 总数量以及运行中的数量均为2:
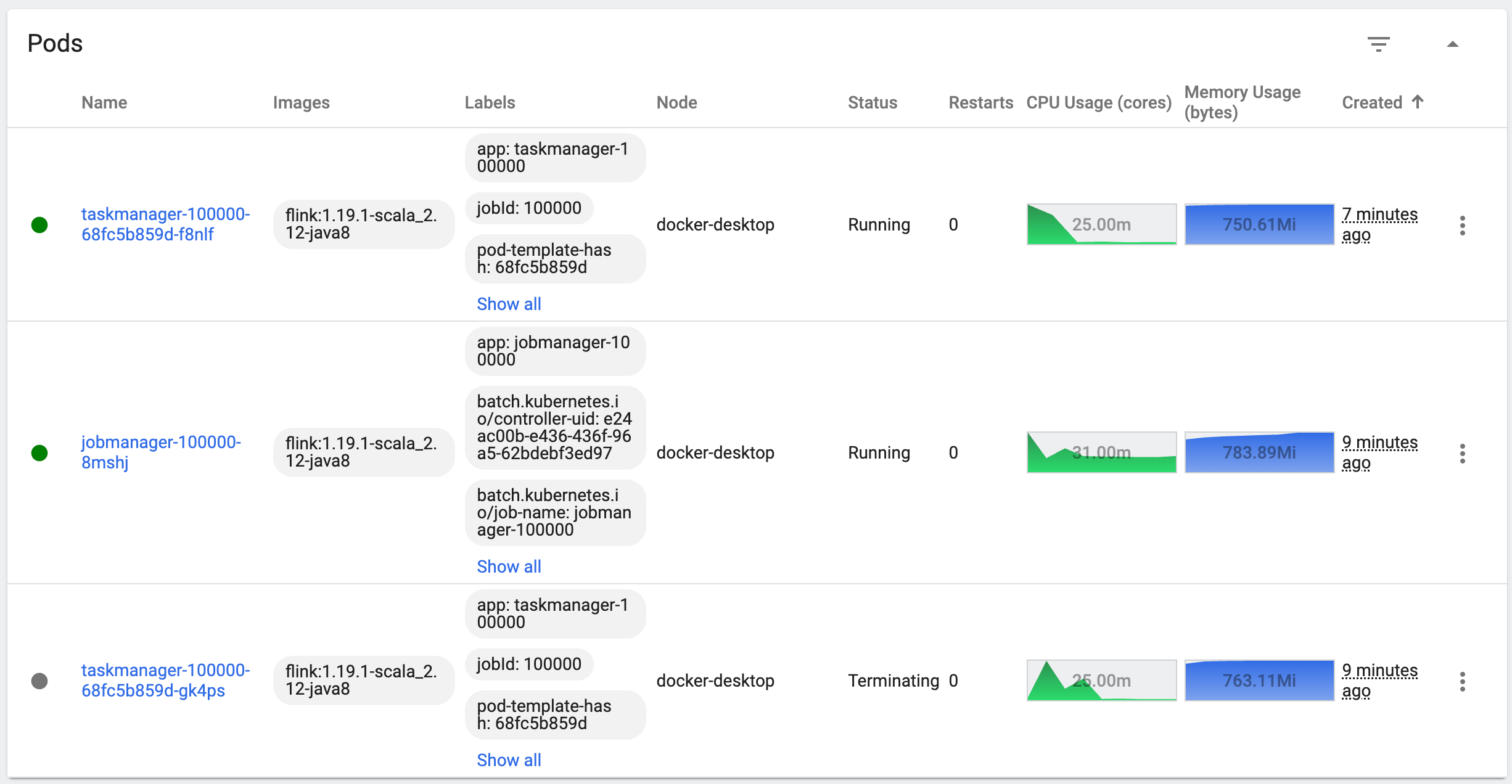
为了方便讲解,这里使用 kubernetes-dashboard 继续查看作业部署的部署情况,如下图:
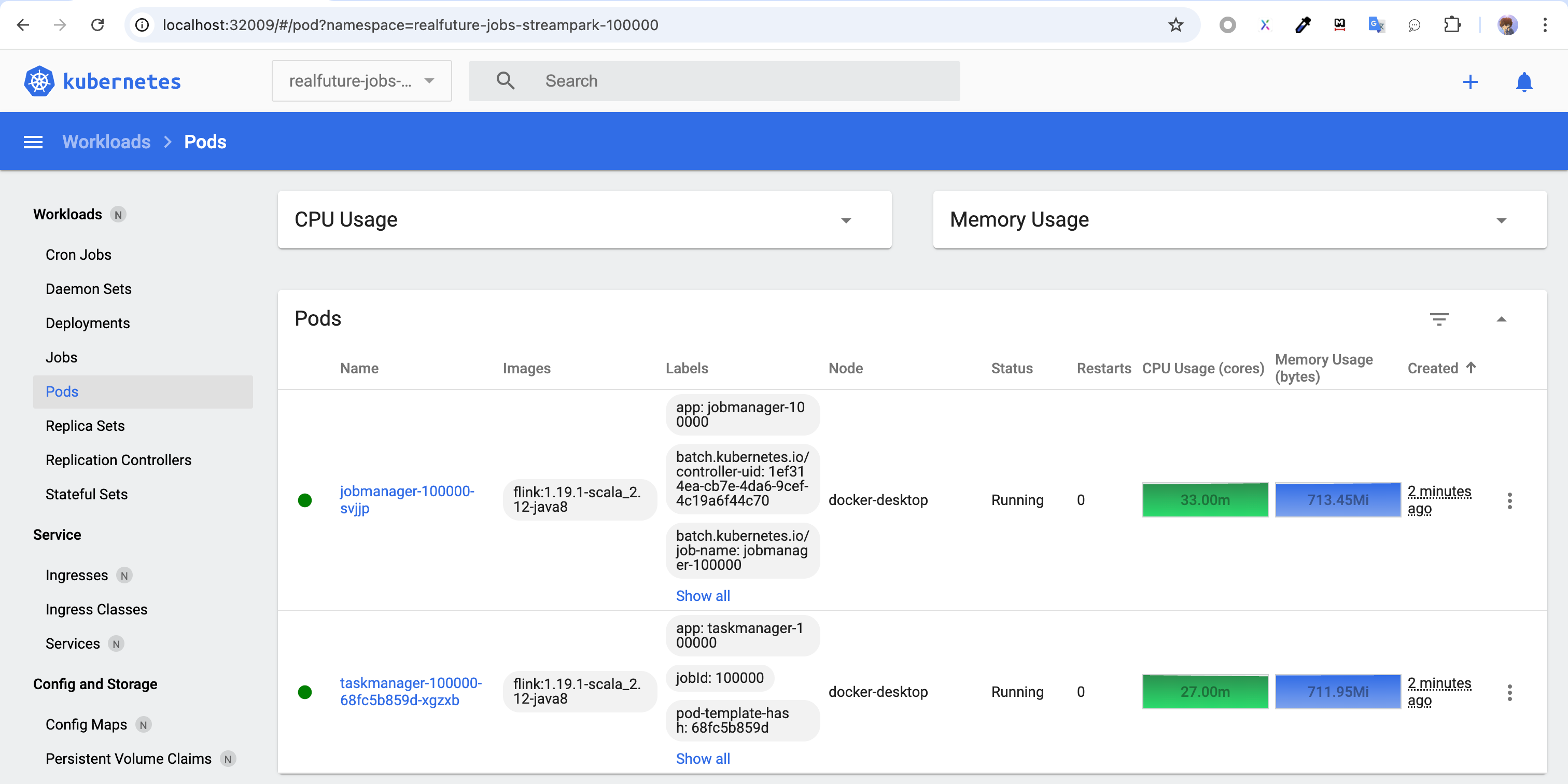
从图中可以看出:
- 作业部署到了 "realfuture-jobs-streampark-100000" 空间,这个空间会自动创建,格式一般为:"realfuture-jobs-空间名-空间ID"。
- 作业分为了两个
JobManager和TaskManager pod,且都只有一个副本。 TaskManager的CPU资源利用率也不高,只有27.00m。
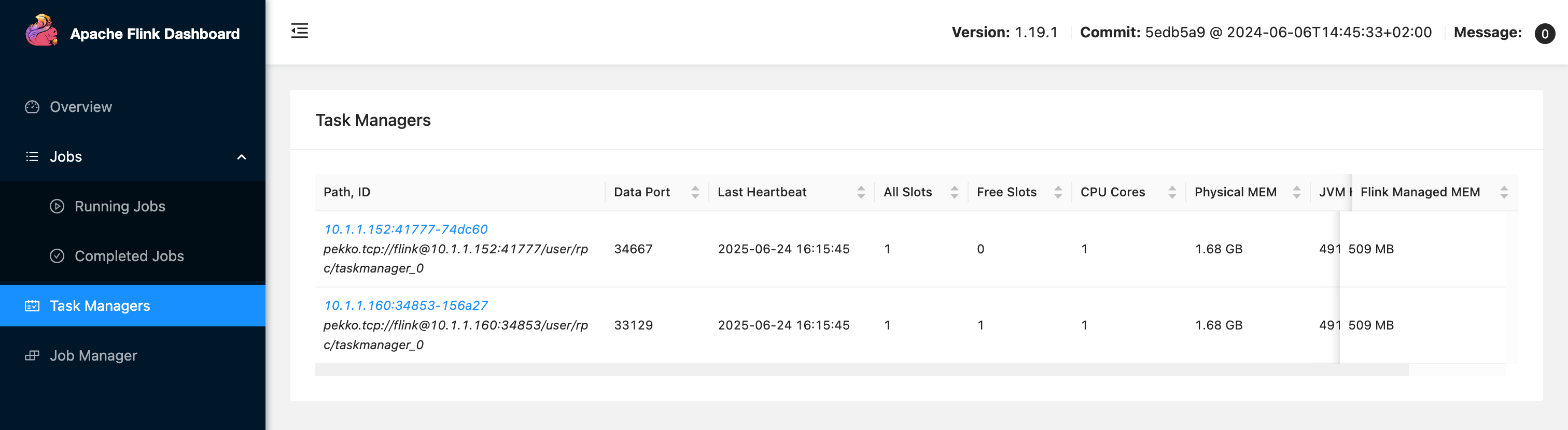
当然也可以通过命令查看资源使用率情况情况:
kubectl get hpa -A

从图中可以看到目前 TaskManager 的资源使用率仅为 2%。
接下来尝试人为对 CPU 进行暴力增压,使其 CPU 飙升。
模拟 CPU 飙升
这里写了一个脚本,模拟使 TaskManager pod 的使用率飙升,核心方法如下:
start_load() {
if kubectl get pod load-generator -n realfuture-jobs-streampark-100000 &> /dev/null; then
echo "Load generator is already running."
else
echo "Starting load generator..."
kubectl run load-generator --image=busybox --restart=Never --namespace=realfuture-jobs-streampark-100000 --image-pull-policy=IfNotPresent -- /bin/sh -c "
for i in \$(seq 1 20); do
while true; do wget -q -O- http://taskmanager-100000:9249/metrics; done &
done
wait
"
fi
}
该方法的逻辑是不断地去请求 TaskManager pod,使其 CPU 不断地飙升,运行该方法前,可以看到作业情况如下:
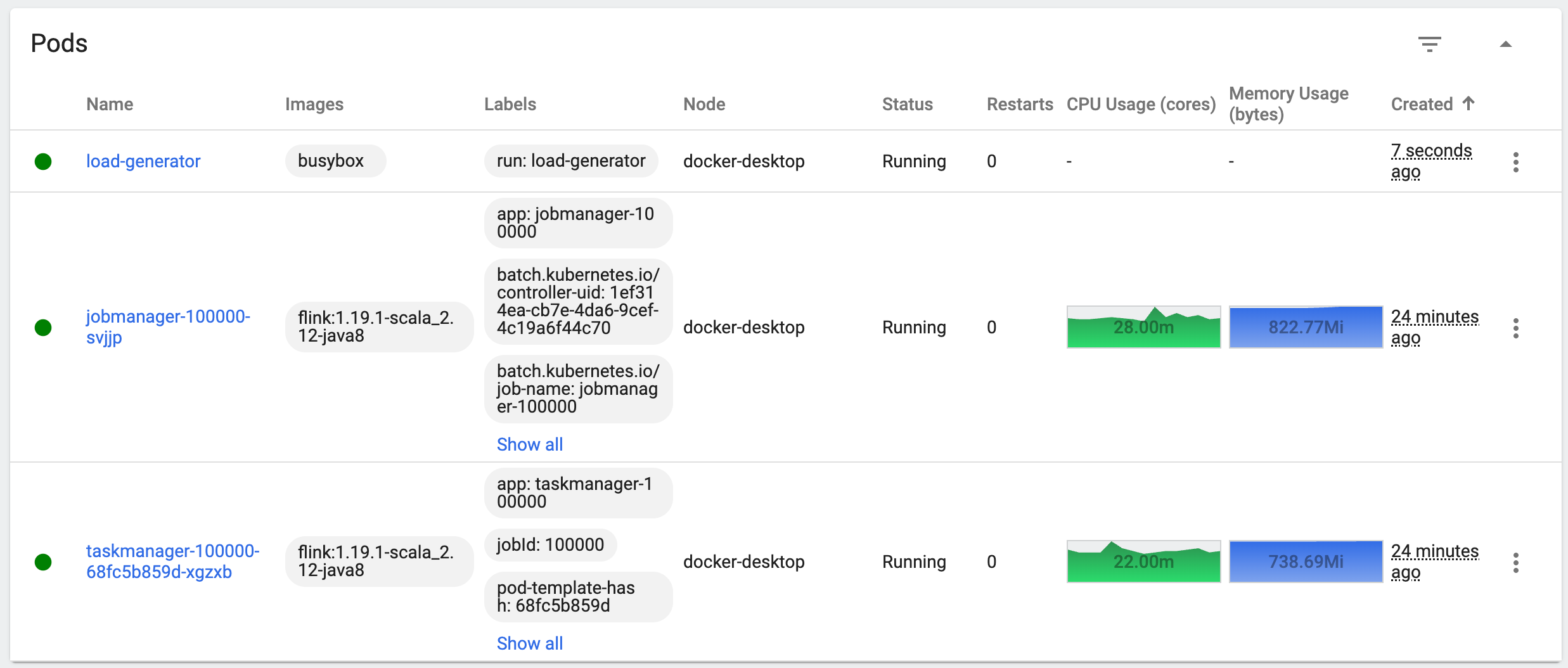
自动扩容
运行一段时间后,可以看到 TaskManager 的 CPU 从 22m 飙升到了 778m:
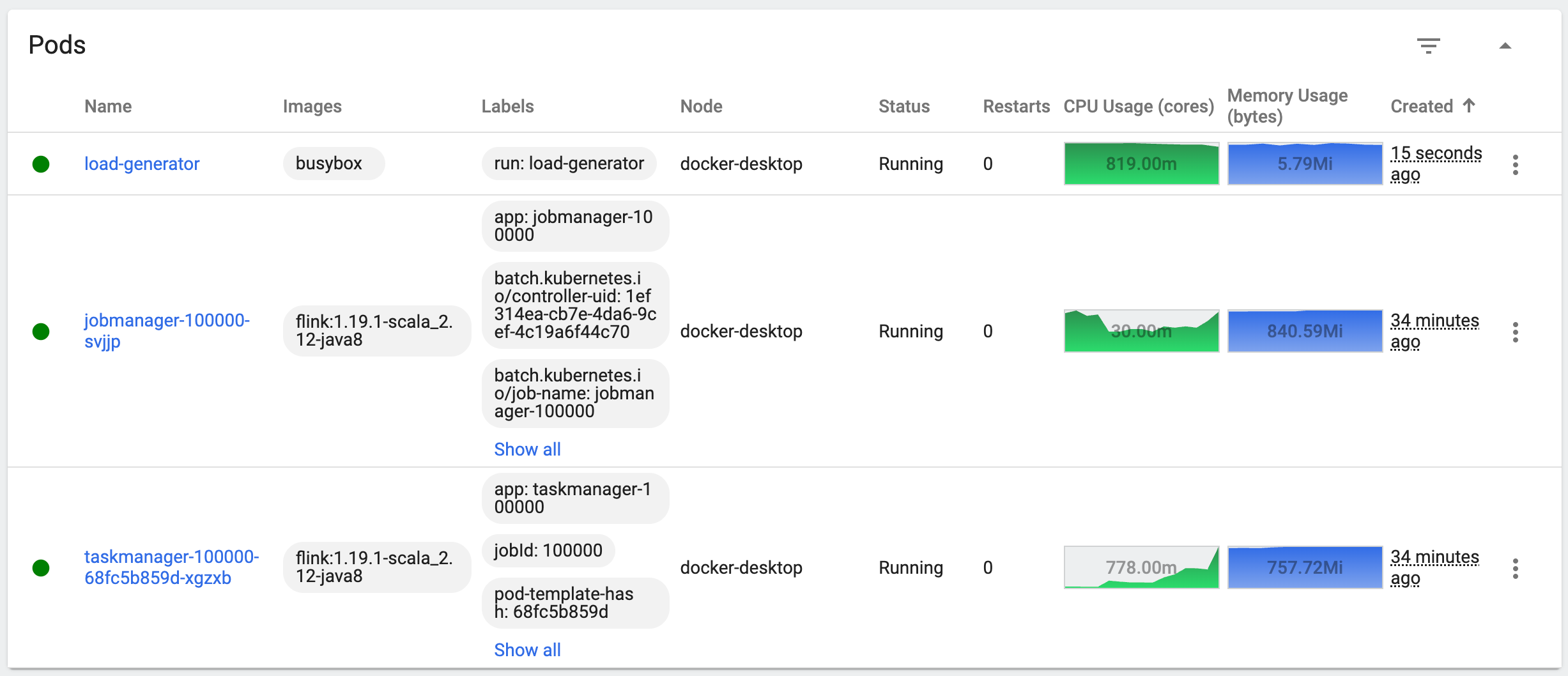
通过运行命令,也可以看到 CPU 占用率为 87% ,远超设定的 65% 的阈值:

这个时候,通过 kubernetes-dashboard 可以看到 TaskManager 的自动扩容多了一个副本:
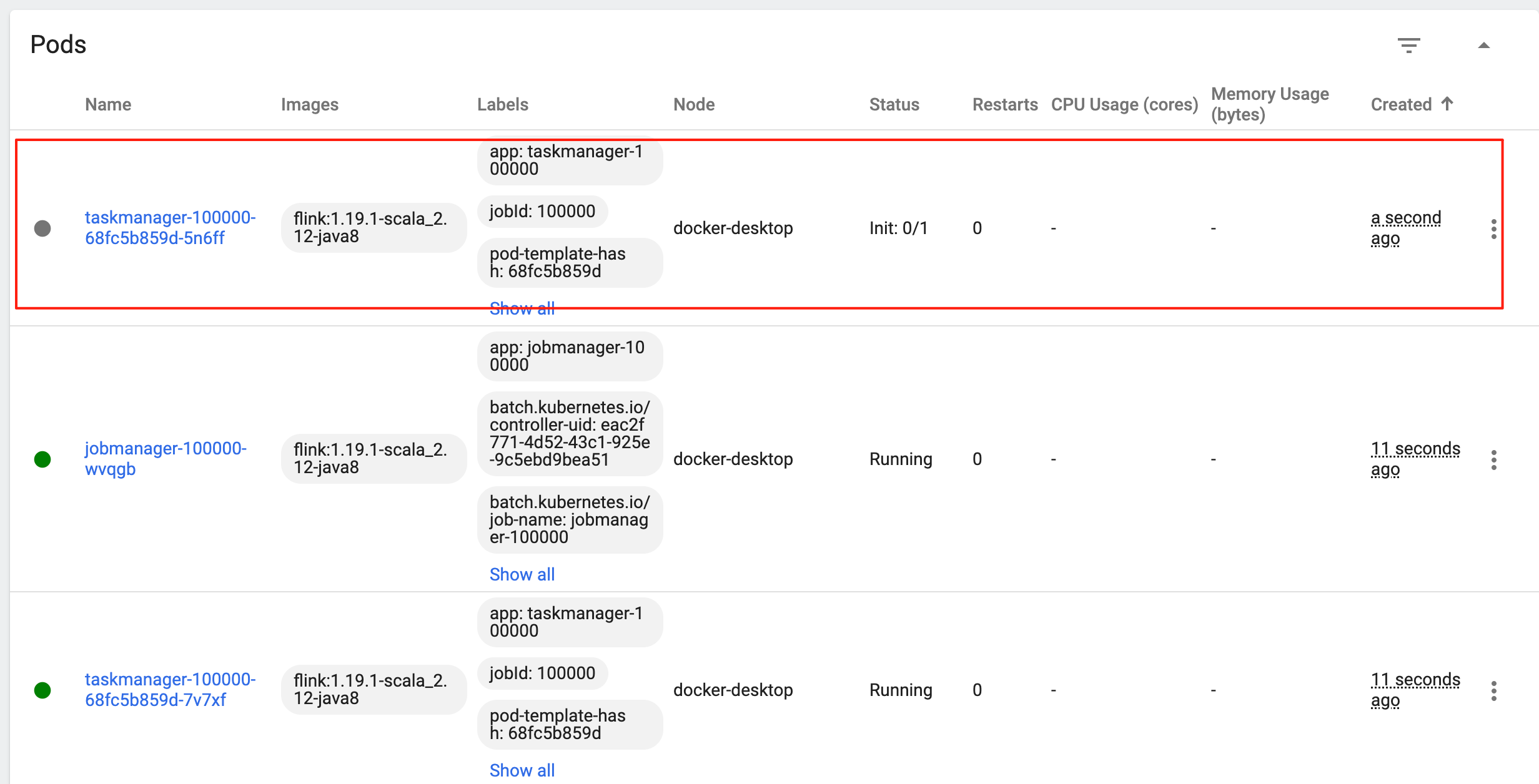
在 Flink Web UI 也可以看到,TaskManager 自动增加了一个:
任务数也从 2 变为了 3,作业自动重启。
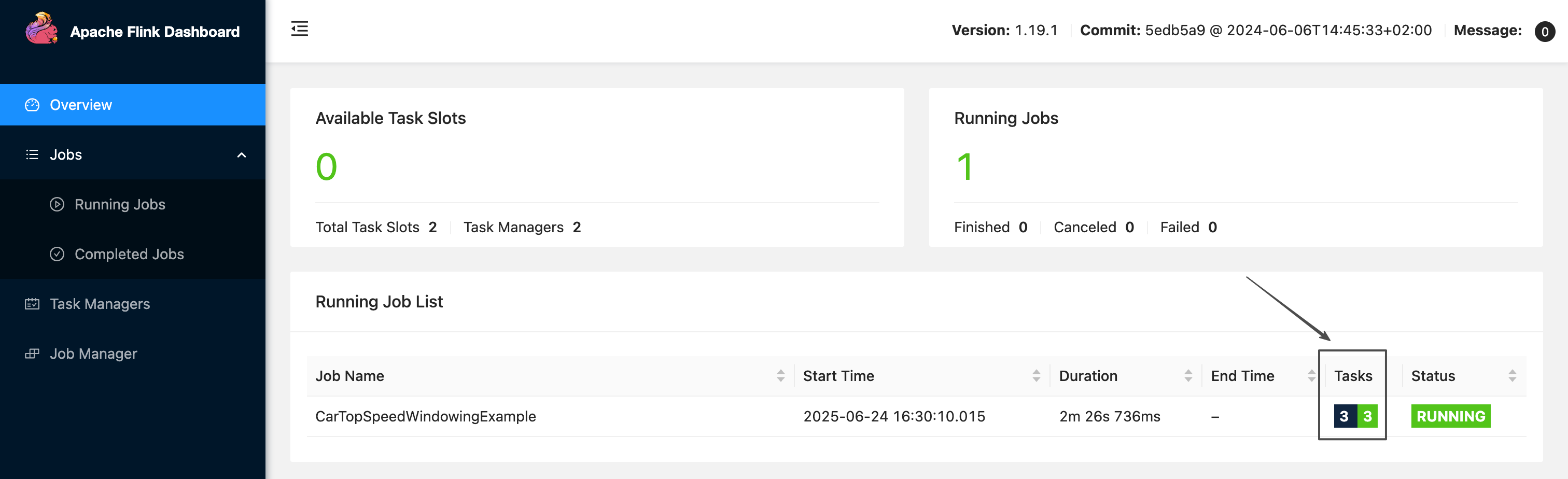
在此返回作业运维中心,可以看到作业稳定运行,全程无需人工干预:
自动缩容
执行停止脚本,模拟 CPU 下降,模拟脚本如下:
stop_load() {
if kubectl get pod load-generator -n realfuture-jobs-streampark-100000 &> /dev/null; then
echo "Stopping load generator..."
kubectl delete pod load-generator -n realfuture-jobs-streampark-100000
else
echo "No load generator running."
fi
}
大约5分钟之后,TaskManager 会进行自动缩容,副本数减 1:
总结
通过本实践可以验证:
Flink作业在Kubernetes环境下,基于TaskManager资源利用率,能够动态实现自动扩缩容,保障作业在负载波动场景下的稳定运行。- 支持多维度扩缩容策略,如
CPU利用率、内存使用率、以及自定义Flink指标(如backlog、延迟、Watermark滞后等),满足不同业务场景的资源弹性调度需求。 - 全流程无需人工干预,作业能够根据实时负载自动扩容或缩容,有效提升资源利用效率与作业稳定性。
- 提供
Flink Web UI、kubernetes-dashboard以及kubectl命令行工具,多维度监控与运维手段,便于作业运行状态的实时观测与管理。
这是一种简单、高效、可落地的 Flink 作业自动弹性扩缩容最佳实践,值得在实际生产环境中推广应用。